Stockage de la donnée
Data-virt : Le service de stockage et de restitution de données
Le service de stockage de données est décomposé en deux sous-services. La partie qui gère les données structurées et permet les recherches, la partie qui stocke les données non structurées.

L’ajout ou la mise à jour de données structurées
Lors de la réception de données structurées qui doivent être insérées dans la base, data-virt effectue les actions suivantes:
-
Contrôle des droits d’écriture de l’utilisateur
-
Chargement des données non structurées si nécessaire (cf chapitres suivants)
-
Alimentation automatique des métadonnées item en fonction des métadonnées utilisateurs
-
Conversion en une requête pour écriture dans la base de données associée
L’accès aux données structurées
Le schéma suivant présente les modules utilisés dans le cadre de l’accès aux données structurés.
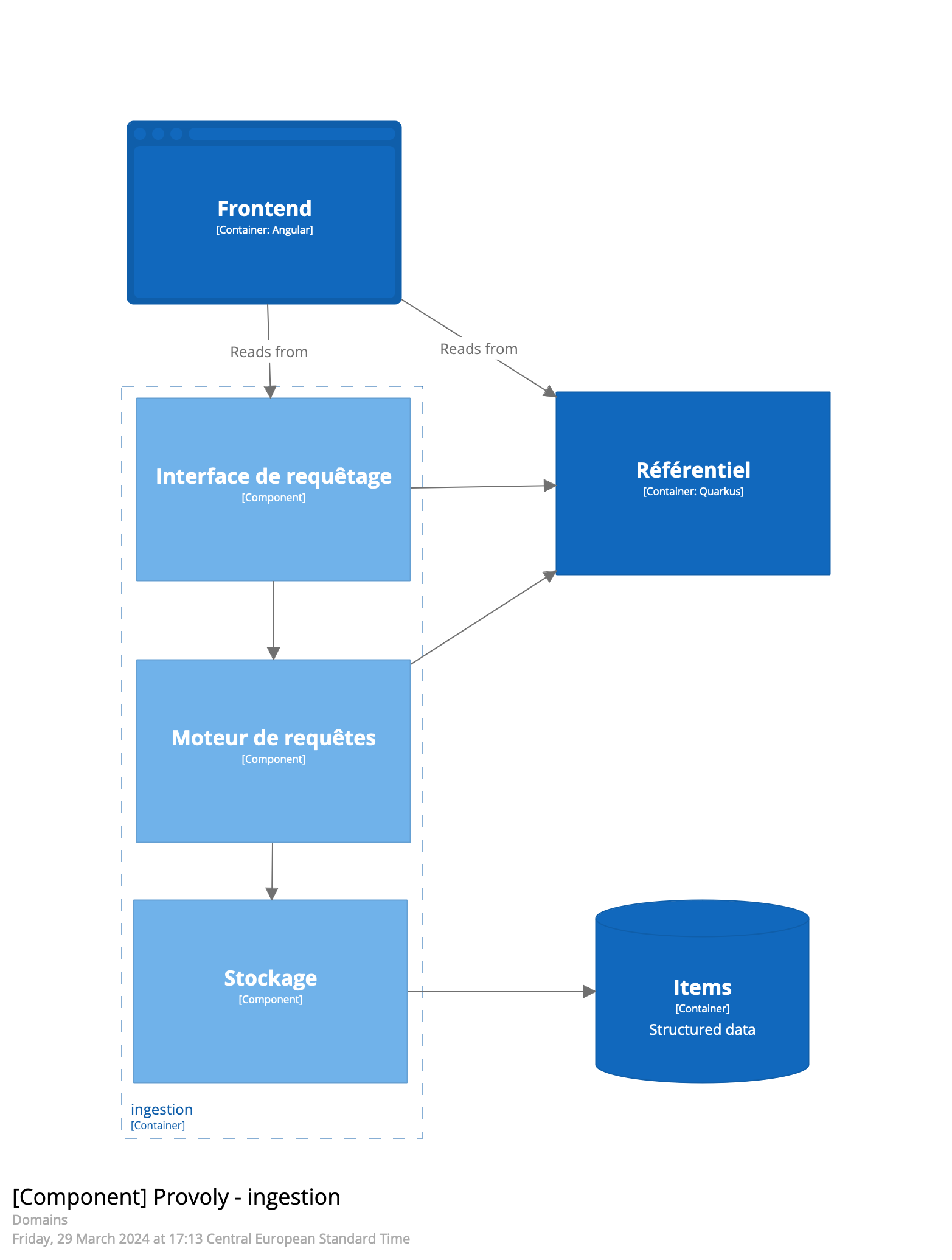
L’interface de requêtes
L’API permettant d’interroger les données utilise une descripton json de la requête à exécuter. Le modèle suivant décrit les principaux objets permettant d’exprimer cette requête :

Une SearchRequest possède une condition de recherche fulltexte. Elle permet de chercher sur l’ensemble des attributs textes de la portée de la requête. Elle se combine avec les conditions optionelles décrites ci-dessous.
Une SearchRequest peut être soit de type MonoClass, soit de type MultiClass
Dans le cadre d’une recherche de type MonoClass, l’identifiant de la classe cherchée doit être fourni.
Une condition est soit :
-
Une condition composée, c’est-a-dire une liste de conditions reliées par un opérateur ET ou OU, qui peuvent être elle-même des conditions composées. Cette définition récursive permet d’exprimer des requêtes complexes.
-
Une condition de type attribut qui permet de filtrer en fonction de critère sur des attributs
-
Une condition de type metadata qui permet de filtrer sur les métadonnées d’un item.
Une recherche MultiClass possède :
-
Une liste de classes optionnelle qui permet de limiter la recherche à un sous-ensemble des classes. S’il est absent, la recherche est effectuée sur l’ensemble des classes déclarées dans le modèle de données.
-
Une liste de FieldCondition qui contiennent l’identifiant du champ, l’opérateur utilisé et la valeur. Pour chaque classe de la liste, la plateforme recherche les items correspondants.
Afin d’appliquer de façon adéquate les filtres ABAC décrit ci-après en interne une requête MultiClass est transformé en autant de recherches MonoClasses que de classes de sa portée.
Les opérateurs sont les suivants :
Opérateur |
String |
Numérique |
Date |
Position |
2nde valeur |
EQUALS |
x |
x |
x |
||
NOT_EQUALS |
x |
x |
x |
||
CONTAINS |
x |
||||
START_WITH |
x |
||||
END_WITH |
x |
||||
GREATER_THAN |
x |
x |
|||
LOWER_THAN |
x |
x |
|||
INSIDE |
x |
x |
x |
||
OUTSIDE |
x |
x |
x |
||
DISTANCE |
x |
x |
Le résultat contient une liste d’items pour chaque classe dans le format suivant :
{
"items": {
"classId1": [{},{}],
"classId2": [{}]
},
"count": {
"classId1": {
"count": 1008,
"accurate": true
},
"classId2": {
"count": 10000,
"accurate": false
}
}
}Les recherches ont une limite (paramétrable) d’items par classe à retourner pour éviter de récupérer un trop grand nombre de résultats qui ralentirait l’application.
La propriété count permet d’avoir le nombre total d’items présents dans le jeu de données, sauf s’il dépasse 10000: on précise alors que la valeur n’est pas correcte.
Il est possible d’ajouter une propriété à la requête de recherche pour augmenter la limite par défaut, sachant qu’elle ne pourra pas dépasser le maxLimit.
Récupérer l’ensemble des items
Il existe deux manières de récupérer l’ensemble des items d’un jeu de données :
La pagination
La récupération de tous les items utilise le mécanisme de search after, qui nécessite un tri. Désormais, le résultat de la recherche possède une propriété searchAfter si un tri est précisé.
Pour avoir la prochaine page de résultat, il suffit d’effectuer la même requête, en y ajoutant la propriété searchAfter (valorisée avec le contenu de la propriété renvoyée lors de la précédente requête), qui permettra de reprendre la recherche là où elle s’est arrêtée.
Cette propriété est un object encodé en base 64 qui contient deux informations :
-
Le searchAfter qui contient la n-ième valeur de l’attribut sur lequel on a trié, n étant le dernier item du résultat.
-
Le point in time (pit) qui est généré avant d’effectuer la recherche. Il permet de d’avoir un tri sur des attributs qui n’ont pas de valeurs uniques, mais aussi de ne pas perdre la pagination en cas de rafraichissement.
Il a une durée de vie de 5 minutes. Au delà des 5 minutes, il n’est plus possible de récupérer les pages suivantes. Il faut recommencer la recherche sans préciser desearchAfter.
Remarque : le point in time n’est pas généré si l’utilisateur effectue un tri sur l’id de l’item
Server-sent events
Un nouveau service permet de récupérer tous les items d’un coup, en utilisant le server-sent events. Le résultat est une liste de paquets de n items, n étant la limite qui a été configuré.
Le searchAfter est automatiquement ajouté à la prochaine requête, puis la recherche continue jusqu’à ce que le dernier résultat soit vide : on a atteint la fin de la recherche.
Recherche nommée
Après avoir effectué une recherche, il est possible de l’enregistrer et la nommer afin de la rejouer plus tard, ou de la partager à d’autres utilisateurs. Les recherches nommées sont considérées comme des sources de données puisqu’elles peuvent être utilisées dans des restitutions.
Source de données
Les sources données sont des sources que l’on peut afficher dans des restitutions. Il en existe plusieurs types :
-
Les recherches nommées
-
Les définitions de jeu de données : Pour prendre automatiquement la dernière version d’un jeu de données en précisant l’id de sa définition.
-
Les jeux de données. À l’inverse, on peut positionner un jeu de donnée en particulier.
Les restitutions sont des widgets configurés pour afficher les données sous forme de graphique, tableau ou carte.
Les graphiques peuvent afficher des données agrégées.
Agrégation
Le service d’agrégations permet de restituer pour une source de données des données agrégées pour des graphiques. Les paramètres sont multiples et peuvent être combiné de plusieurs manières :
-
Il est impératif de connaître l’id de l’attribut sur lequel il faut agréger les items :
aggregatedBy. Les items seront par défaut compté pour chaque aggregation. -
Si on ne souhaite pas faire un compte d’item, il faut preciser une
operationà effectuer sur une autre attribut qui sera passé dansvalueField; Suivant l’opération demandée, le valueField n’acceptera que certains types d’attributs. -
On peut définir un pas dans
intervalou un interval de date dansdateIntervalpour agréger les données dans un histogramme. -
Il est possible faire un regroupement en série d’agrégations en précisant l’attribut à regrouper dans
groupBy. -
Un tri peut être demandé (ascendant ou descendant) avec
order.
Les opérateurs disponibles ainsi que leurs types d’attributs acceptés sont les suivants :
Operateur |
String |
Numérique |
Date |
COUNT |
|||
MAX |
x |
||
MIN |
x |
||
AVG |
x |
||
SUM |
x |
||
CARDINALITY |
x |
x |
|
MEDIAN |
x |
||
Q1 |
x |
||
Q3 |
x |
Rq : l’opérateur COUNT sert à compter le nombre d’item ayant une valeur différente pour l’attribut aggregatedBy.
Le résultat retourné est également différent, puisqu’il comporte une liste de clé valeur à afficher dans un graphique:
{
"operation": "max",
"values": [
{
"key": -46.8753791,
"value": 10.0
},
{
"key": 44.8753791,
"value": 15.0
}
]
}Dans le cas de regroupement en série, value est remplacé par groupBy de cette manière :
{
"operation": "max",
"values": [
{
"key": -46.8753791,
"groupBy": [
{"key": 10, "value": 10.0}
]
},
{
"key": 44.8753791,
"groupBy": [
{ "key": 0, "value": 15.0}
]
}
]
}Filtre sur source de données
Il est possible de rajouter des filtres sur des attributs lorsqu’on effectue une requête sur des sources de données. Un filtre est composé d’un id d’attribut, d’un opérateur, ainsi que la valeur à filtrer. Une seconde valeur peut être passée en paramètre si l’opérateur prend deux valeurs. Le ou les filtres mis en paramètre dans l’url sont convertis en "AttributeCondition" et une recherche de type MonoClass est effectuée. Si plusieurs filtres sont présents dans la requête, alors on effectue une condition composée de type "AND" entre chaque filtre. Dans le cas où la source de donnée est une recherche nommée mono classe, on combine les conditions de recherches avec les filtres en utilisant un "AND".
Pour l’instant il n’est pas possible de filtrer sur une recherche nommée de type MultiClass.
Les filtres peuvent être utilisés sur une aggregation.
Les filtres ABAC
Le module de filtre Abac possède toute la logique permettant de déterminer les restrictions d’accès de l’utilisateur effectuant la requête et les injectent dans la requête demandée. Seul les items visibles par l’utilisateur sont retournés. Une seconde passe met à jour la visibilité des attributs bas" sur les règles Abac basé sur les métadonnées. Pour ne retourner que les items et les attributs visibles. Seuls les n premiers items satisfaisant les critères sont retournés. L’ensemble des relations dont au moins un des items du résultat est source ou destination est ensuite ajoutée au résultat retourné.
Moteur de requêtes
Le moteur de requête transforme alors la requête en une requête adaptée au stockage associé à la classe. Cette traduction tardive permet d’envisager de mettre en œuvre d’autres moteurs de translation qui permettrait de supporter d’autres types de bases de données.
Stockage
Plusieurs bases de données vivantes sont disponibles pour le stockage des données directement consultables par l’utilisateur. Le choix de la base de données est faite par l’utilisateur au moment de la création du modèle. La base de données par défaut est Elastic.
Elastic
Plusieurs moteurs de recherche ont été évaluées avec les critères suivants :
-
Capacité de gérer de grands volumes de données
-
Capacité de gérer des requêtes diverses et complexes
-
Maintenance réduite
-
Open Source et libre
Au vu des critères, Elastic possède les avantages et inconvénients suivants par rapport aux autres bases :
| Avantages | Inconvenient |
|---|---|
Possibilité d’ajouter des attributs sans modification de structure de la base. Les suppressions peuvent être gérées via des scripts écrits dans un langage dédié. |
Support géodésique limité au WSG84 |
Les systèmes de requêtes dynamiques, c’est-à-dire les requêtes créées dynamiquement par le système en fonction de critères utilisateur (système de recherche par facettes par exemple) pose un challenge d’administration des indexs. Elastic ne possède pas cette difficulté puisque l’ensemble des données sont stockées dans un index. |
Support des géometries non conformes et gestion de volumétrie limité |
Les fonctionnalités de recherche full text native |
|
Le support des fonctions de recherche géométrique |
Cependant, le support géométrique de Elastic reste limité (notamment en ce qui concerne la volumétrie, les référentiels de coordonnées)
Postgis
Postgis est la base de données la plus adaptée au stockage et traitement de données géodésiques.
| Avantages | Inconvenient |
|---|---|
Permet de traiter de grosses volumétries de données géodésiques |
Recherche full text non native |
Support de multiple CRS et de géométries non conformes |
Modification complexe de structure de données |
Support de fonctions de recherches géométriques complexe |
Kuzzle
Kuzzle est un stockage utilisé pour gérer des données iot. Il se base sur Elasticsearch pour insérer et rechercher les données,
et possède donc les mêmes avantages et inconvénients de ce dernier.
Néanmoins, il est possible d’utiliser Kuzzle de la même manière que Postgis et Elasticsearch en créant un modèle de données avec le stockage KUZZLE.
Sinon, Kuzzle intègre un plugin iot qui impose une gestion des données particulières et fonctionne donc différement des autres stockages.
Assets et mesures
Un asset correspond à l’équipement dont on souhaite récupérer les mesures. Les données d’un asset seront mises à jour,
contrairement à ses mesures qui seront historisées et récupérées à intervalle de temps régulier.
Pour cela, deux storages sont présents dans provoly pour les distinguer : KUZZLE_ASSET et KUZZLE_MEASURE.
Création des modèles de données
Le modèle de données dans Provoly doit être similaire à ce qui est déclaré dans Kuzzle et ne génère pas d’index ou de collections. En effet, la définition des modèles d’assets et de mesures est faite dans le code source de Kuzzle et génère un mapping spécifique.
Un jeu de données doit également être défini pour la remontée des données :
| Stockage | Jeu de données |
|---|---|
|
|
|
|
Il est prévu que la génération de ces modèles dans la plateforme soit faite automatiquement.
Récupération des données
Dans kuzzle, l’ensemble des assets se trouve dans une seule collection assets, et sont différenciés par une propriété présente dans le mapping : model.
Toutes les mesures de tous les assets sont également dans une seule collection measures, et sont différenciées pas la propriété model pour déterminer à quel asset elles correspondent et measureName
pour le type de mesure.
-
Pour récupérer les assets, une condition de type
metadataest ajoutée aux critères de recherche pour ne récupérer seulement les assets correspondants au modèle de données en question. -
Pour récupérer les mesures d’un asset, deux conditions de type
metadatasont ajoutées aux critères de recherche pour ne récupérer que les mesures demandées en fonction de l’asset.
Les données des assets et mesures étant stockées directement dans Kuzzle, il n’y pas d’import via un csv ou un shapefile via provoly pour le moment.
Structure des données dans Kuzzle
Le tableau ci-dessous décrit l’ensemble des index utilisés pour la gestion des assets et mesures :
| Index | Collection | Description |
|---|---|---|
|
|
Contient les modèles de données de tous les assets et mesures |
|
|
Contient les données de tous les assets |
|
|
Contient les données de toutes les mesures de tous les assets |
L’index tenant-name n’est pas créé au démarrage de Kuzzle. Il doit être créé avant de recevoir les données avec l’appel :
POST {{kuzzle_url}}/_/device-manager/engine/{{tenant-name}}La génération des collections assets et measures est faite automatiquement à la création de l’index.
Le module d’accès aux données non structurées
Ce module a pour rôle de stocker et de restituer la donnée non structurée, ainsi que d’assurer les contrôles d’autorisation d’accès.
Il n’interprète pas la donnée. Il peut stocker des données comme :
-
Texte brut
-
Fichier CSV ou similaire
-
Document formaté (pdf, office, html, …)
-
Image
-
Vidéo
-
Enregistrement sonore
-
…
Le stockage des données est assuré par fournisseur externe qui permet d’utiliser le modèle d'object storage via une interface compatible S3.
Dans le service de virtualisation, si un objet possède un attribut d’un objet de type raw, il fait alors référence à un objet dans le lac de données. Cet attribut est un identifiant unique (guid) qui est utilisé comme nom d’objet dans le S3.
Il ne supporte pas de fonction de recherche sur le contenu des données. L’ensemble des recherches sont supportées par le service de virtualisation. Un accès au dataLake se fait toujours après un accès au service de virtualisation qui fournit l’id de la données souhaitée.
Il n’y a pas de gestion de droit au niveau du S3, seul un compte de service est autorisé à y accéder et les droits sont portés par le module data-virt. Si l’utilisateur en cours à accès à l’attribut référençant l’objet dans data-virt alors il a accès à l’objet dans le lac de données.
Architecture du stockage
Le package com.provoly.virt.storage contient l’ensemble des éléments relatifs à la gestion des échanges avec les différents stockages.
L’ensemble des opérations passent par le point d’entrée Storage[Action]Adapter qui implémente l’ensemble des opérations communes aux differents stockages.
La classe StorageAdapterUtils permet de récupérer le service de stockage associé au modèle à l’aide du StorageQualifier précisé (via annotation) sur chaque service.
Exemple avec les actions sur les modèles
